NEWS 更新情報・お知らせ
【要保存】本当は公開したくない!?4ヶ月でサピックスの国語偏差値14UPの秘密

執筆者紹介:木村友哉
オンライン個別指導塾「医塾」代表。「生徒ファースト」の指導で、担当生徒のために年間で最大約1900年分の過去問を解き、個別指導講師として14年以上、多くの生徒を難関大・医学部へと合格させている。指導科目は生徒から要望があれば持ち前の勉強量を活かし、数学・英語・現代文・小論文・推薦対策など多岐にわたる。医塾では主に数学と小論文を担当。東京大学文3(英語・数学を担当)や、千葉大学医学部(数学を担当)名古屋大学(英語・現代文を担当)、慶應大(英語・数学・小論文を担当)など、難関国公立大学や国私立医学部に多くの生徒を合格させた実績を持つ。その他推薦対策(志望書の添削、面接対策)も行っており、筑波大学(生物資源学類)、慶應(看護、文、総合政策、環境情報)、上智大学(外国語学部英語学科)等、数々の生徒を合格させている。

プロ講師紹介の木村先生のページはこちら
こんにちは、医塾の木村です。
皆さん5月のマンスリーはいかがでしたでしょうか。
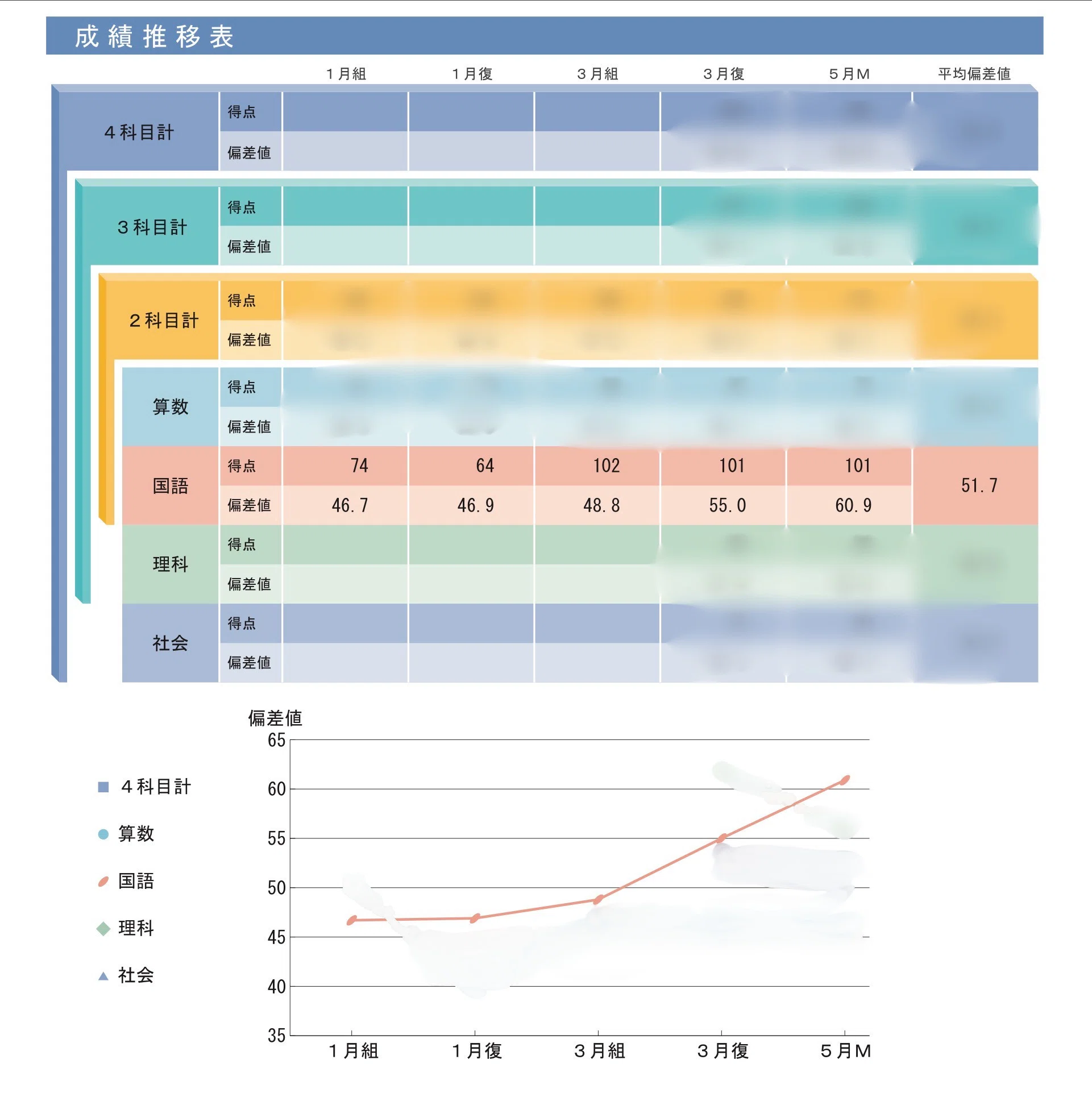
今回は、SAPIXに通う小学4年生の国語の偏差値を46(1月)→60超え(5月M)にUPさせた方法を共有していこうと思います。
SAPIXを含め大手中学受験予備校に低学年から通う生徒が増えていますね。中学受験において、国語は実は怖い科目だと思っています。
全く点数が取れない人からすると、どうすれば点数が上がるのかもわからず、やる気も失われていきます。
他方で、何となく(そこそこ)取れてしまう生徒にとっては、「そんなにやらなくてもいいよね」と勉強が後回しになり、結果的に受験で足を引っ張る科目になることも多いです。
勉強しても短期的な成果が見えにくい科目なので、最低1年かかる科目だと個人的には思っていますが、ある特徴を持つ生徒は短期的に点数・偏差値を伸ばすことが可能です。
国語の点数が取れていない時に「これはやっておいた方が良い」こと
国語の偏差値が~45くらいまでの生徒は「漢字」・「言葉ナビ」・「知の冒険」がきちんと消化できていない可能性が高いです。
デイリーチェックやマンスリーの大問1・2あたりで失点が多いものと思われます。
*漢字等は既に満点です、という場合は、この記事は点数アップではなく時短テクという形で見てもらった方が良いかなと思います。
実はこのタイプの生徒は大チャンスです。読解力を短期的につけるのは中々難しいですが、知識を固めることは短期間でもできます。そのため、点数や偏差値に現れやすく、頑張った→点数が伸びた→できるかもしれない・・・と子どものやる気につながります。
少し本筋から離れますが、勉強を頑張るようになる方法の第1位は「成績が上がること」だと思っています。
「頑張ったら成績が上がる・・・じゃあどうやって頑張らせたらいいのか・・・」と考えがちですが、点数が取れると勝手に頑張れるものなので、逆説的ですが先に点数を取らせるのも有効な手法なんですよね。(これは塾の発想かもしれませんが)
点数が取れる→周りからも褒められるし、点数が伸びて自分もうれしい。自信もつく。→次はもっと頑張ろう・・・と正のスパイラルに入るのが理想だと思っています。
閑話休題。とにかく点数につなげるという視点から考えるとデイリーチェックやマンスリーの大問1や2は宝の山です。
ということでここからは具体的にどうやって知識を詰めていったかについてまとめていきます。
結局は「どれだけやったか」である。
急に知識が覚えられるようになる・・なんて魔法のような勉強法はありません。地道な努力あるのみです。
国語の知識を定着させるためには結局のところどうやって「量」をこなすかに尽きると思います。言い換えれば、いかに(嫌がらず)反復して知識を定着できるかが勝負ということです。
読解問題にコツや解法は存在しますが、知識はある意味で筋トレに近いですね。
令和の時代ですが、この点だけは昭和のスポ根精神が結構大事だと思っています(笑)
ただし、暗記の際にインプット偏重になりすぎないことが大切です。アウトプットの機会を増やす方が知識の定着は上がります。
そのため、
テストをする→できなかったものを覚え直す→再テストをする・・・と繰り返していくことが有効です。
ただ、それをお家でやるのは大変です・・・。SAPIXの場合課題の量が多くて「テストなんて・・・そこまでやってられないよ・・・」と保護者側もギブアップしてしまうようなレベルです。
そんな忙しい保護者様のために、生成AIでランダムテストを作るプロンプトを用意しました。(PCが使えない場合はスミマセン・・・)
私も実際に生徒にAIを利用して問題を読み取り、ランダムテストを作って何度も生徒にやらせています。テキストをそのまま取り組ませると場所で覚えてしまったりするので、ランダムに問題を入れ替えてテストをするのが大事ですね。
その結果、デイリーチェックでは、それまでは6割前後が普通だったのですがアウトプットを繰り返すことで8割や9割を超えるようになりました。今まで漢字のミスがとても多かったですが、マンスリーでも漢字1問ミス、慣用句(言葉ナビ)は満点でした。
是非試してみてください。
(実践編)AIにテストを作ってもらうためのプロンプトと使い方
使い方:言葉ナビの(見開きではなく)1ページ分写真に撮って、ChatGPTに添付して、以下のプロンプトを実行すればエクセルのテストを作ってくれます。現状は類義語・対義語ですので、形式が変わる101ページ以降はまた修正が必要になりますが、そのまま写真を撮って読み込んでも、ある程度読み取ってはくれます。(需要があれば作ります)
ちなみに、もし読み取りがうまく行かない場合は「読み取れていないのでやり直してください」と指示するとやり直してくれます。(やり直すと大体は使えるものが出力されます)
~プロンプト~
この画像の問題を正確に読み取ってください。
【最重要】
まずOCRだけで決めず、
文脈・漢字・問題の流れも利用して校正してください。
特に、
・似た漢字
・送り仮名
・対義語 / 類義語
・問題番号
・解答対応
を重点的に確認してください。
「問題文」などの仮文字は絶対に入れず、
必ず画像から読み取った実際の文章を出力してください。
──────────────────
【読み取り方法】
画像を次の3つの領域に分けて認識してください。
① 上段(問題文)
② 中段(対義語 / 類義語)
③ 下段(問題文)
──────────────────
【OCR後に行うこと】
■ 1
問題番号と問題文を対応させる
■ 2
対義語 / 類義語を対応させる
■ 3
文脈を利用してOCRミスを修正する
■ 4
上段・中段・下段の内容を統合する
──────────────────
【出力するExcelファイル】
xlsx形式で、
1つのExcelファイルとして出力してください。
──────────────────
【シート構成】
■ シート1〜
画像1枚ごとに1シート作成
1行目にはA列など列名は記載しないこと
シート名:
「1-14」
「15-30」
のように、
そのページの最小番号-最大番号
──────────────────
【各シートの形式】
■ 上段
A列:問題番号
B列:□
C列:問題文
D列:解答欄(空欄)
──────────────────
■ 中段
E列:上段の解答
F列:⇔ または =
G列:下段の解答
──────────────────
■ 下段
H列:□
I列:問題文
J列:空欄
──────────────────
【追加シート】
最後に次のシートも追加してください。
──────────────────
■ 「ランダムテスト」
今回の画像で読み取った問題全体のランダムテストです。
A列:問題番号(1から振り直し)
B列:問題文
C列:解答欄(空欄)
D列:解答
・問題順はランダム
・問題番号は1から振り直す
──────────────────
【Excel設定】
・列幅を自動調整
・折り返し表示
・MS明朝系フォント
・罫線あり
・文字化けしないようにする
──────────────────
【重要】
・空欄( )は消さない
・問題番号をずらさない
・OCRミスを修正してから出力する
・読み取れない場合は前後の文脈から推測する
・問題文を省略しない
・ランダムテストにも正しい問題文と解答を入れる
最終的に、
「OCR済み問題データ」
と
「ランダムテスト」
を
同じExcelファイルにまとめて出力してください。
おまけ:漢字のテストを作る場合
漢字も1ページ1枚ずつ写真を撮って、以下のプロンプトとセットでChatGPTに指示をするとランダムテストを作ってくれます。
ただし、精度が甘い(違う漢字を問題だと読み取ってしまったり、下線部の範囲が異なったり・・・)のでおまけとしています。私の場合は出力した後に何度かChatGPTとやり取りをして精度を高めるか、面倒なので残りの修正はエクセルファイル上で手直ししています。
~プロンプト~
この画像の国語・漢字テストを正確に読み取ってください。
【最重要】
OCRだけで決めず、
文脈・漢字・送り仮名・問題の流れも利用して校正してください。
特に、
・同音異義語
・似た漢字
・送り仮名
・読み問題 / 書き問題の区別
・問題番号
・解答対応
を重点的に確認してください。
「問題文」などの仮文字は入れず、
必ず画像にある実際の文章をそのまま出力してください。
──────────────────
【出力するExcelファイル】xlsx形式で、1つのExcelファイルとして出力してください。
──────────────────
【手順】
■ 1
画像全体を読み取り、
まず問題の種類を判定する。
例:
・読みの問題
・書きの問題
──────────────────
■ 2
問題番号順に、
問題文を正確に整理する。
──────────────────
■ 3
各問題の漢字・読みを文脈から補正する。
例:
・建国 / 健康 / 健全
・固有 / 固定 / 固い
・約 / 約分 / 予約
などを文脈で区別する。
──────────────────
■ 4
問題と解答の対応関係を維持したまま、
問題順をランダムに並び替える。
──────────────────
■ 5
以下の形式で表形式出力する。
【Excel形式】
A列:問題番号
B列:問題文
C列:解答欄(空欄)
D列:解答
※1行目に「A列」「問題番号」などの列名を書かないこと
※問題番号は1から振り直すこと
※最初の行からデータを出力すること
※タブ区切りで出力すること
※問題番号は元の番号を維持すること
※読み問題と書き問題を分けること
※句読点も可能な限り再現すること
──────────────────
【出力例】
読みの問題
1 なべに白菜を入れる。 はくさい
7 無理ばかり言ってこまらせる。 むり
書きの問題
3 算数で、やくぶんして答えを出す。 約分
8 くぎを打ってこていする。 固定
──────────────────
【Excel設定】
・列幅を自動調整
・折り返し表示
・MS明朝系フォント
・罫線あり
・文字化けしないようにする
・解答に対応する問題文の単語に下線を引く
──────────────────
【注意】
・OCR結果をそのまま出さず、必ず文脈校正する
・「ボート」と「ボール」などOCRミスを修正する
・「きょくげい→曲芸」のように文脈から補正する
・読み問題では「漢字→読み」
・書き問題では「ひらがな→漢字」
として整理する
・解答欄(C列)は必ず空欄にする
おまけ2:再テストの場合
ChatGPTに再度お願いするのが面倒であれば、エクセルファイルの右端の空欄に「=rand()」で乱数を発生させて、データの並べ替えをすることで順番を入れ替えたりすることもあります。ただ、この辺りは(慣れていないと)面倒なので、毎回作り直してもらっても良いかなと思います。
「ChatGPTに順番を入れ替えたランダムテストをもう一度作って」と打てば作ってくれます。
以上
□プロ講師専門オンライン塾「医塾」とは
医塾は、中学受験・高校受験・大学受験に対応した完全1対1のオンライン個別指導塾です。授業はすべて社会人プロ講師が担当し、生徒一人ひとりの志望校、学力、性格、学習状況に合わせて指導します。医学部受験、難関大学受験、難関中学受験、小論文対策、英検対策にも対応し、オンライン自習室での学習管理、授業録画の再視聴、授業外質問、進路相談までオンラインで完結できます。
・公式HP
HPからのお問い合わせはこちら:https://ijyuku.com/contact/
公式LINEからのお問い合わせはこちら:https://lin.ee/bBGn3t1
・公式X(Twitter)、公式Instagram、公式TikTokはこちら
【公式X(Twitter)】医塾 | 中高大受験のプロ講師専門オンライン塾 -リーズナブルな価格で最高の指導を全国に-